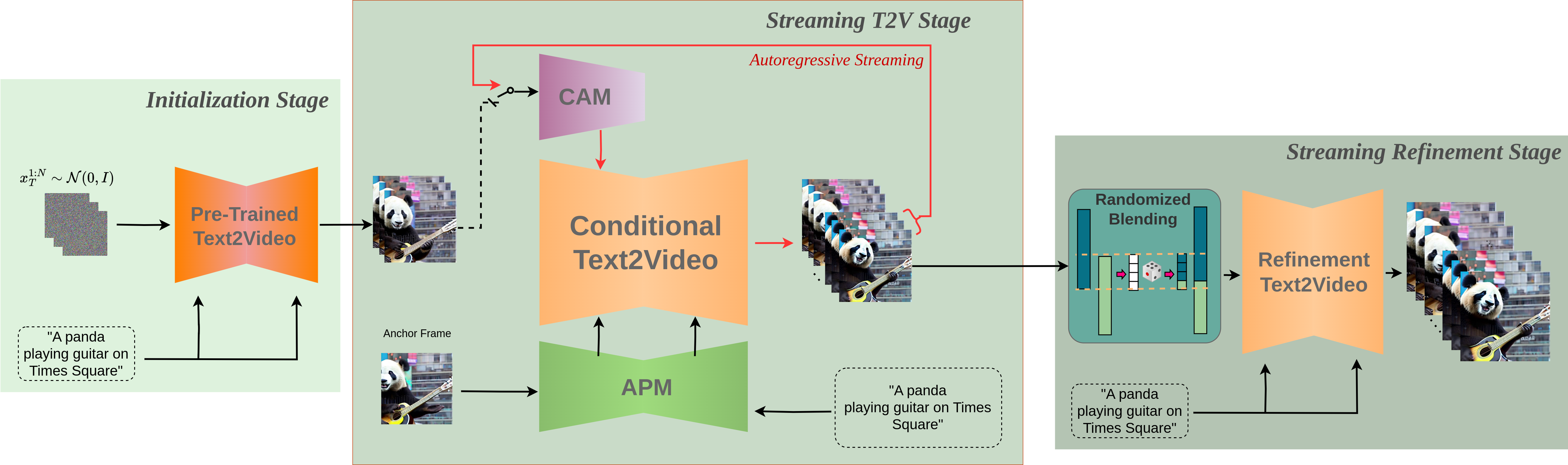
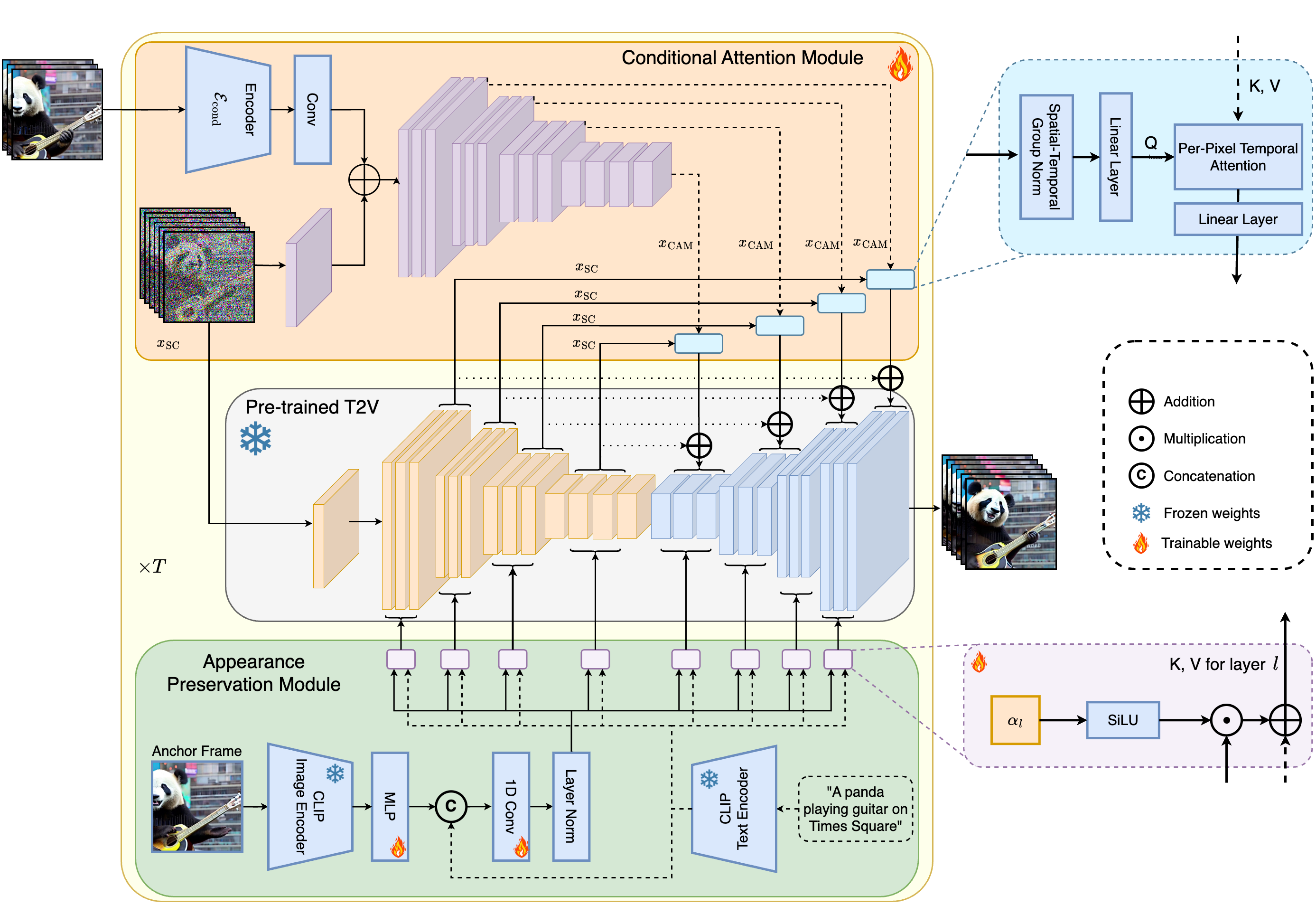
StreamingT2V is an advanced autoregressive technique that enables the creation of long videos featuring rich motion dynamics without any stagnation. It ensures temporal consistency throughout the video, aligns closely with the descriptive text, and maintains high frame-level image quality. Our demonstrations include successful examples of videos up to 1200 frames, spanning 2 minutes, and can be extended for even longer durations. Importantly, the effectiveness of StreamingT2V is not limited by the specific Text2Video model used, indicating that improvements in base models could yield even higher-quality videos.